Organizers of the 23rd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM SIGSPATIAL 2015) have challenged the GIS community to participate in a coding competition about finding the shortest path (space and time based) under polygonal obstacle constraints.
Shortest path algorithms are widely used today, and they are vital for routing services such as Google Maps, Microsoft Bing or Here.
This competition was focusing on single source single destination shortest path algorithms where the shortest path between two nodes of the graph is the target for the search. The contest also adds difficulties by introducing the polygonal obstacles which mean they generated polygons what should be avoided during the shortest path generation.
The contest masters defined the competition’s target as the calculated shortest path quality and the computation time of calculation (excluding all the I/O operations). Unfortunately, there was no exact definition of the evaluation method they used, but this guideline was enough for the contesters to optimize their approach.
One of the best-known algorithms for this problem (SSSP) is the A* algorithm. I selected this algorithm because the task defined only one shortest path search per run and this algorithm requires no preprocessing as it can be run on the data after it is loaded into the memory. To get the fastest result, I have selected C++ for the implementation language and I tried to avoid overhead on object oriented data structures, so I picked up the adjacency list data structure implemented as simple arrays. The algorithm maintains an inner data structure to pick up a node in every iteration. This data structure must support quick extractMin operation as well as quick insertion method. One of the best available options for this specification is the heap data structure. Studies are suggested to use different heap approaches for the A* algorithm what I wanted to investigate therefore I have included two versions of the heap data structure: binary heap and a 4-ary heap.
The A* algorithm allows us to choose between search directions (forward, backward, bi-directional). To investigate which direction can be the best for the competition, I have implemented all three of them and did a quick in-house evaluation to find out which is the winner approach.
Before I introduce the result, let’s have a look at the example data given by the competition masters. I implemented a quick application to convert the example file into a well-known text format file which then can be loaded into QGIS.

The example file contains a road network with 42408 nodes and 96850 directed links between nodes. The link/node ratio for this graph is something that someone would expect from a graph represents a road network.
There is only one thing what I want to bring into the attention. The practice amongst GIS map digitization people is to build up a curved street with many nodes and links. You can see an example in the following image.

This discovery can give a chance for optimization. When the shortest path algorithm considers its iterations, it is always doing node by nodes. If you consider a long highway which has a long curvature, then when the algorithm considers that highway segment, it has to do many iterations. However, if this segment would be represented by only one link, then the algorithm could evaluate that segment much quicker.
The following example shows what the proposed simplification should achieve.

Applying this simplification gives the following output for the example data file.

After running the simplification algorithm, the road network simplified to 86194 links (-11%). There is, however, an unexpected behavior for this simplification. As you can see in the following image, some of the nodes have been lost their links.
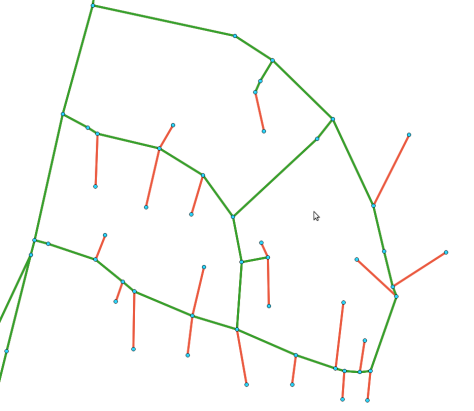
The explanation for this behavior is described by the following image.

Now everything was ready up for the experimentation. In the first step, I was curious about how the simplification algorithm could help to speed up the search. I have run the complete application which has four different parts (reading files, preprocessing data, shortest path calculation, writing out the results) exactly 10 times to avoid runtime fluctuation caused by the operating system’s task scheduling policy. I have picked up an origin and destination node for the application which seemed to be one of the longest. The simplification is inserted into the phase when the application creates the necessary arrays to run the shortest path algorithm. The simplification itself adds time to the execution time but I expected to have benefit when the search uses the simplified road network.

Unfortunately, my quick experiment showed that using the simplification algorithm actually slows down the overall shortest path calculation, because the algorithm couldn’t get more speed up then the extra time caused by the road network simplification. However, if the challenge would be a batch of shortest path calculations (not only one) or the road network would contain more highways then the simplification could have a serious impact on the runtime.
For the second run, I wanted to know what version of the A* algorithm is the quickest to solve the problem. I have run the forward, backward and bidirectional version of the A* with the available two heap implementations (binary heap, 4-ary heap).

According to the literature, the bidirectional A* algorithm should find the shortest path faster than the forward or the backward version. My measurement resulted in the opposite result. The forward implementation required 1362 (length-based) and 541 (time-based) iterations, the backward needed 3453 (length-based) and 977 (time-based), the bidirectional took 1662 (length-based) and 5125 (time-based) iterations. The runtime analysis showed even more difference between the bidirectional and the other versions. The large runtime difference was caused because the bidirectional version requires two heaps (one forward and one backward heap) during the calculation and the data cannot be cached properly however when the algorithm has only one heap, the data can be cached and accessed very quickly. I have run a quick memory usage statistic analyses to find out this is true or not. Valgrind confirmed this behavior because the shortestPathCalculation function caused 5792 (forward), 19464 (backward), 70983 (bidirectional) cache misses (D1mr).
Based on the measurements, I have submitted my application contains the forward A* algorithm using the 4-ary heap plus the introduced road network simplification method. This solution was ranked as 5th valid submission. Unfortunately, the contest masters didn’t give more explanation about their final judging method after publishing the result. For me, it was a great exercise and I have learned a lot. Implementing the most simple GIS method can be very painful using iterative programming languages and algorithms theoretically faster than others behaves differently in practice. Let’s hope that the next years Giscup will be focusing again an interesting problem and I will be able to contribute to that competition as well.
The source code is available on GitHub at the following link.
